
Recently, I wrote about trying to figure out a way to automatically produce visualizations of STM32 peripheral mappings from their datasheets. Unfortunately, it didn’t go too well; I had trouble parsing the output from the command-line pdftotext utility, so I ended up having to manually clean up each peripheral table after it was half-parsed by a script.
I was thinking of trying to write a better parsing script, but before diving into that rabbit hole I took another look at open-source PDF-parsing programs and found Tabula. It is an MIT-licensed utility with one goal: extracting tables from PDF files. And it seems to work very well with ST’s datasheets.
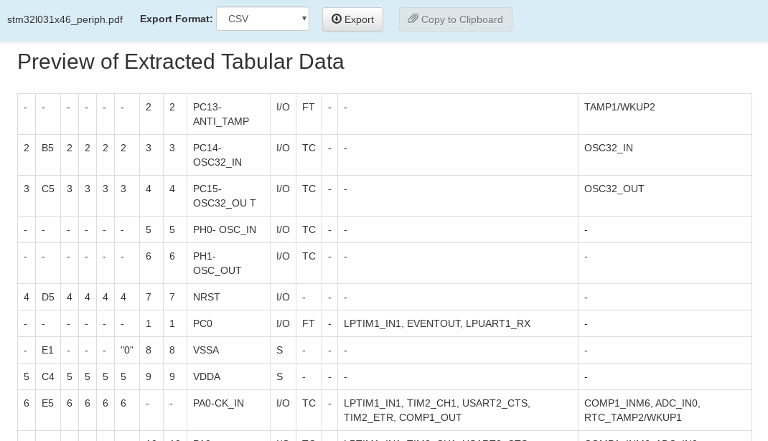
Tabula has a nice local web interface which gives you previews of the table data that it will export from a PDF.
Step 1: Download Tabula
Tabula runs on Java, so it’s simple to set up on just about any platform. They have good installation instructions on their website and GitHub readme file. If you are using Linux, you can download and unzip the tabula-jar-<version>.zip version of the latest release to get a runnable JAR file.
Following the instructions in the README.md file, once you unzip the file and cd into its tabula/ directory, you can start running a local server with the command that the readme file suggests:
java -Dfile.encoding=utf-8 -Xms256M -Xmx1024M -jar tabula.jar
Once it starts up, you should be able to navigate to http://127.0.0.1:8080 in a browser to access the Tabula UI. There is also a command-line version of the project, which will probably be better for setting up an automatic process. But for now, it’s nice to use the visual selection tools which the UI provides.
Step 2: Parse a Datasheet
The Tabula UI makes it pretty easy to import files, but importing and working with large PDF files can also be slow and difficult to navigate. The process is easier if we only upload the pages of the datasheet which contain the relevant tables. There are dozens of ways to extract a few pages from a PDF file, but I used a tool called qpdf. Here’s an example command to extract pages 39-44 from a file:
qpdf --pages input.pdf 39-44 -- input.pdf output.pdf
Most PDF viewers will probably be able to save page ranges, too. Once you’ve extracted the pages of interest, you can upload the PDF to your local Tabula server like you would upload a file to a normal website:
Tabula’s index page
Once you’ve uploaded your file, click ‘Import’ and wait for the process to finish. Once it does, you should see a preview of the PDF file:
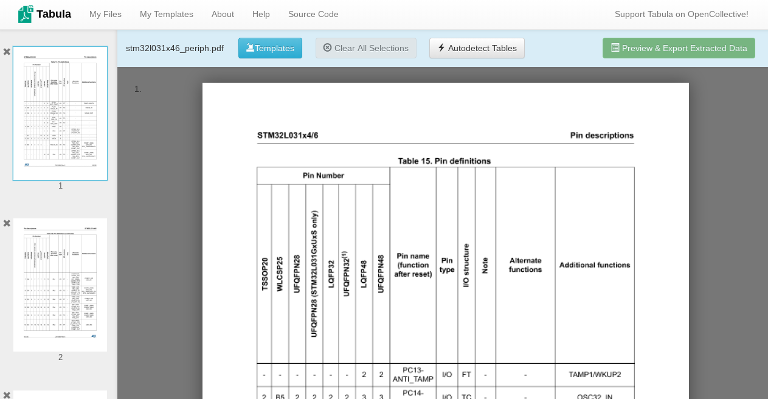
Tabula’s preview interface
You can click and drag to select rectangular areas for the program to process, so try selecting the entire table on the first page. I decided to omit the top rows, since they are repeated on each page:
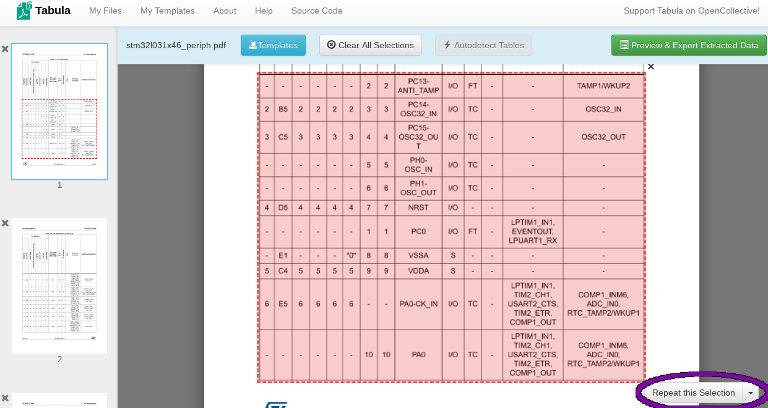
Click and drag to select areas of tables which you want to transcribe.
Once you’ve selected the area of interest, you can click the ‘Repeat this Selection’ button (circled in purple) to select the same area on every other page. In this case, it’s a nice timesaver. But be sure to double-check each page to make sure the boundaries line up, especially the last one:
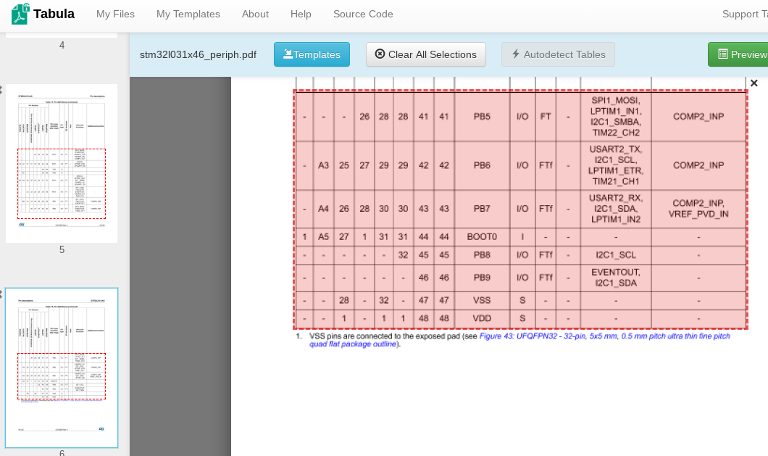
You can drag the edges of a selection to change it if covers part of the document you don’t want.
You can click and drag on the edge of a selection to modify it. Once you’re happy that your selections cover all of the table cells, click the ‘Preview & Export Extracted Data’ button.
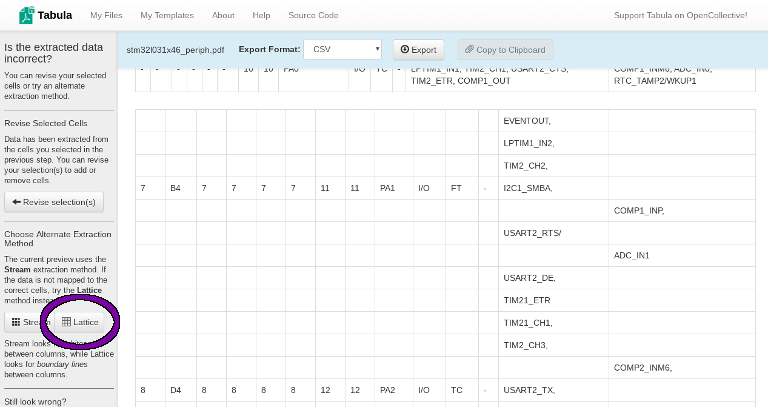
Tabula’s default algorithm does the same thing as `pdftotext`.
Whoops, that doesn’t look quite right. In fact, it looks a lot like the output produced by pdftotext – most of the peripherals are on their own rows. This would still be easier to parse than the output of my Python scripts – you can find row boundaries by looking for the lack of a trailing , or / characters – but there’s an even better option. Click the ‘Lattice’ button (circled in purple above), and Tabula will look for lines instead of text layout to infer cell boundaries.
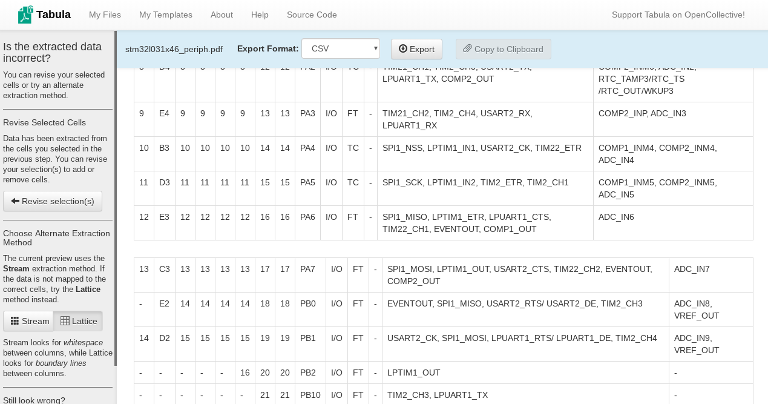
The ‘Lattice’ option seems to work great
Now you can just click the ‘Export’ button and you’ll get a CSV file. I added a ‘CSV to LaTeX’ script to the last post’s GitHub repository, with the same syntax as last time:
python3 pin_tabula_ingest.py <file>.csv <pin_column>
And like with the other script, the pin_column option is which of the datasheet’s packages you want to generate a table for; it’s a number counting up from 0 starting at the left-most column.
Conclusions
After running the Python script and converting the LaTeX files with pdflatex <file>.tex, you get similar PDF outputs to the last post which can be imported into Inkscape, Photoshop, etc.:
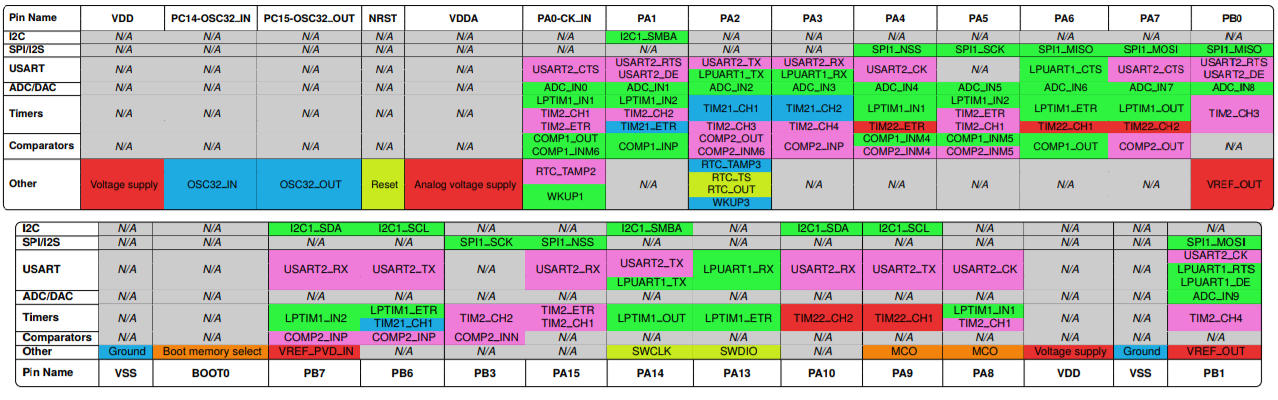
Tables generated from Tabula’s CSV files.
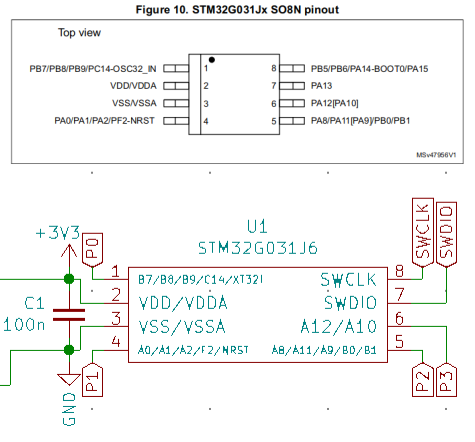
But using Tabula’s “Lattice” formatting option eliminates most of the the tedious and error-prone manual steps from the previous post. Talk about a relief – I didn’t really like the thought of editing more than a few of those garbled table outputs by hand. And now that the table-generation step is nearly automatic, it’s possible to make images for larger chips without getting bored to tears:

STM32L475VG pin:peripheral visualization


{kind=link}